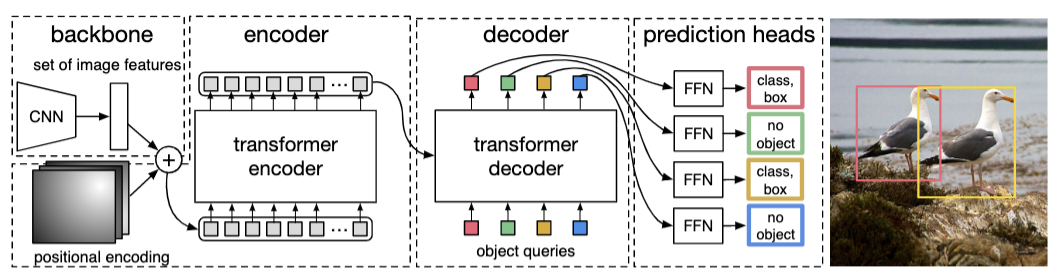
Transformer的前世今生
引言
Transformer,用过都说好。Transformer统治了NLP的半壁江山后,已经开始大规模蚕食CV的诸多任务了。这篇文章总结了Transformer的诞生和里面的具体细节,作为自己的总结文章bia :raising_hand:。
1. 机器翻译的发展
研究员们为了进行机器翻译,得到你现在使用的Google翻译,百度翻译等等翻译引擎,从1950年就开始了努力。他们尝试过各种各样的方法,比如一大推略显朴素和僵硬的既定规则,或者是设定一些翻译的范例和prototype,又或者使用数据驱动的方式,借助数以万计的翻译数据来设计深度学习模型来进行自动化的翻译。从发展历程来看,我们有了以下这样几种翻译方案:
- 「基于规则的机器翻译RBMT」
- 「基于范例的机器翻译EBMT」
- 「统计机器翻译SMT」
- 「神经机器翻译NMT」
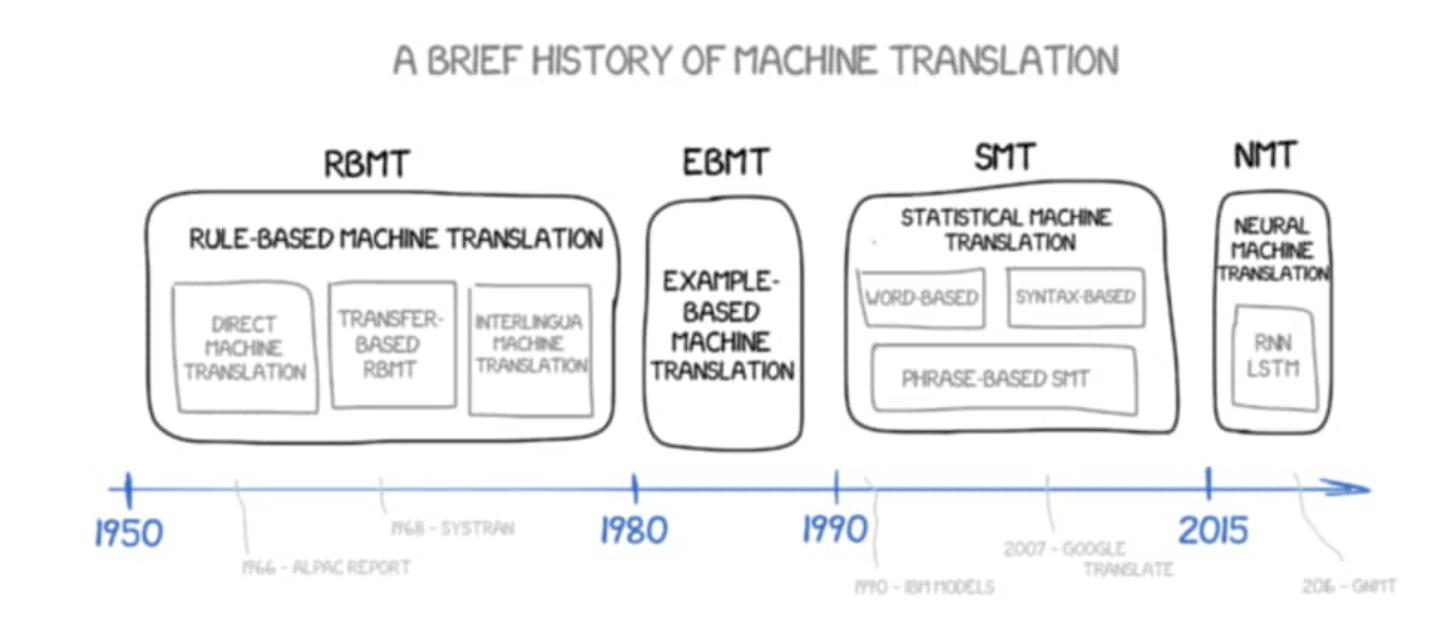
RBMT,EBMT距离我们太远,就不再细细讲述,我们简短回顾一下SMT方案和NMT方案。
1.1 基于统计的机器翻译
典型的SMT模型中有基于短语(phase)的PBMT。基于短语的统计翻译,将基本的翻译单元从原来的整句调整到了短语级别,被切分的短语不一定具有任何语法意义,在歧义消除,局部排序,解码效率上有一定的优势,降低了机器翻译系统的所要面对的复杂度,表现出了较好的模型健壮性,常常作为统计机器翻译系统研究的baseline。
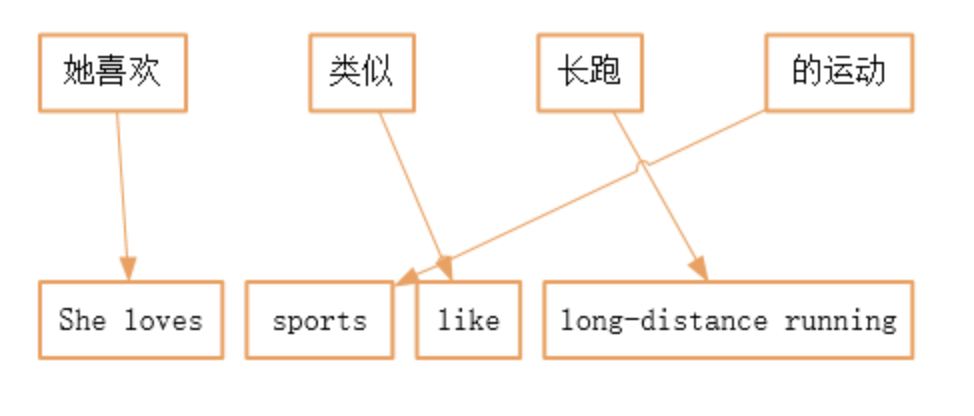
1.2 基于神经网络的机器翻译
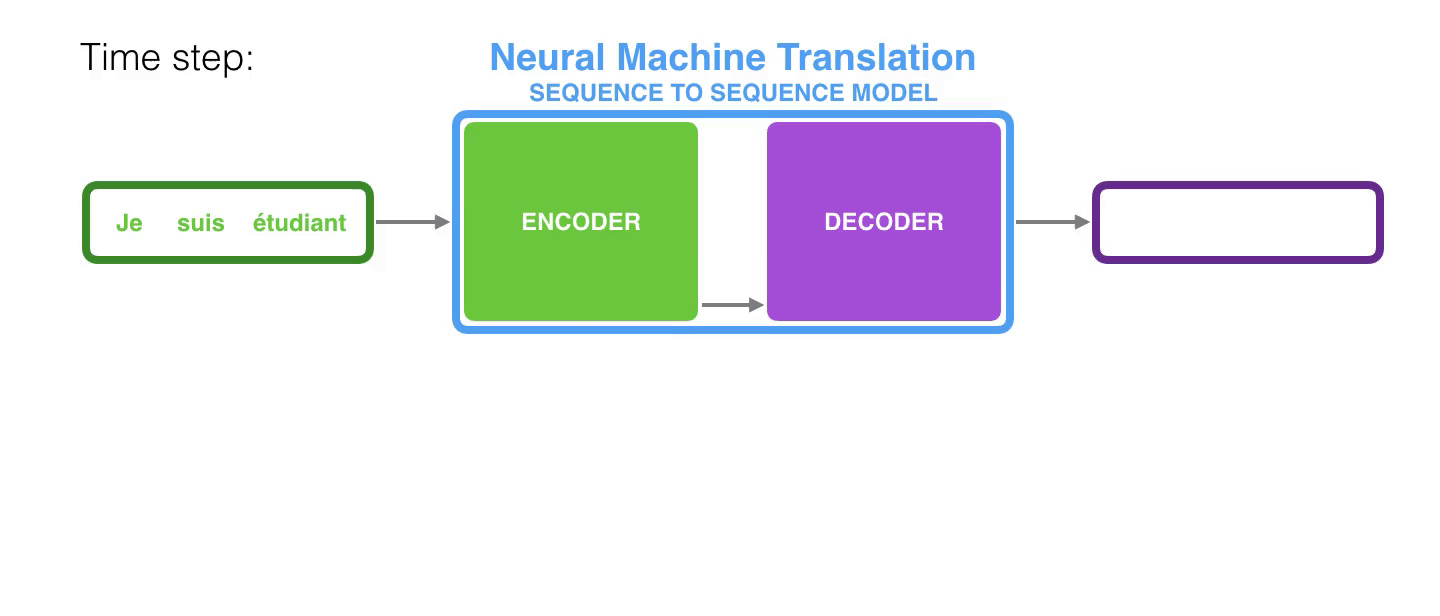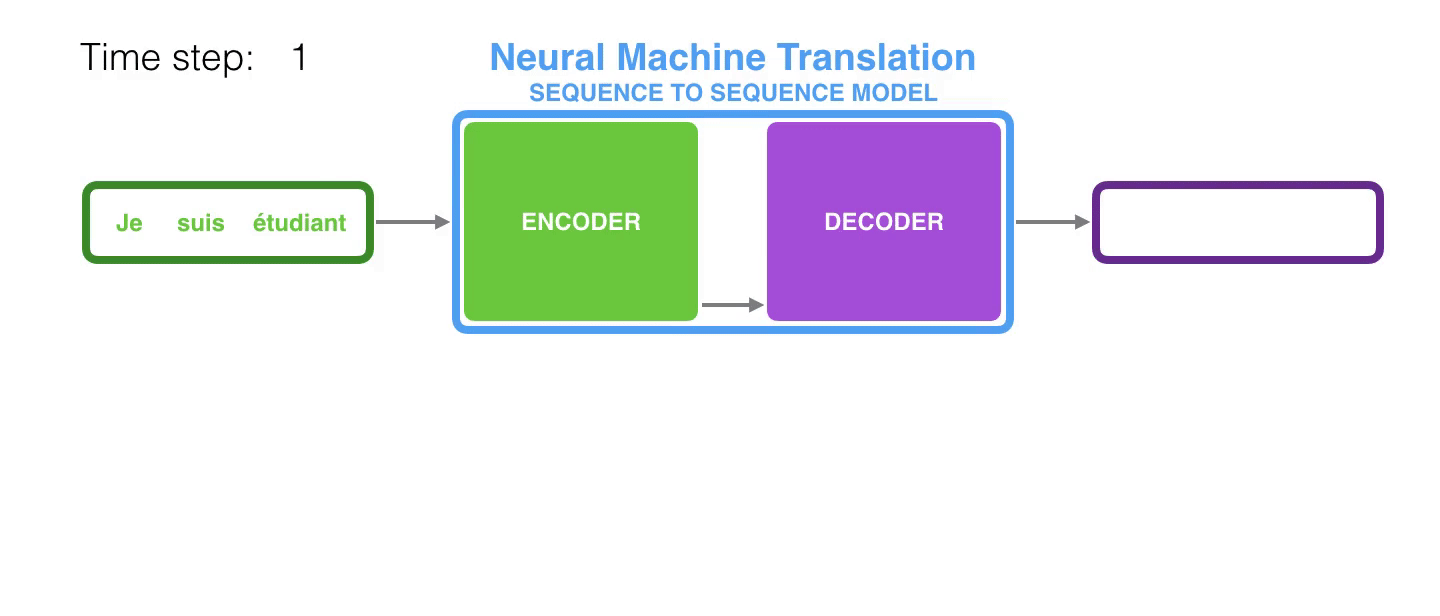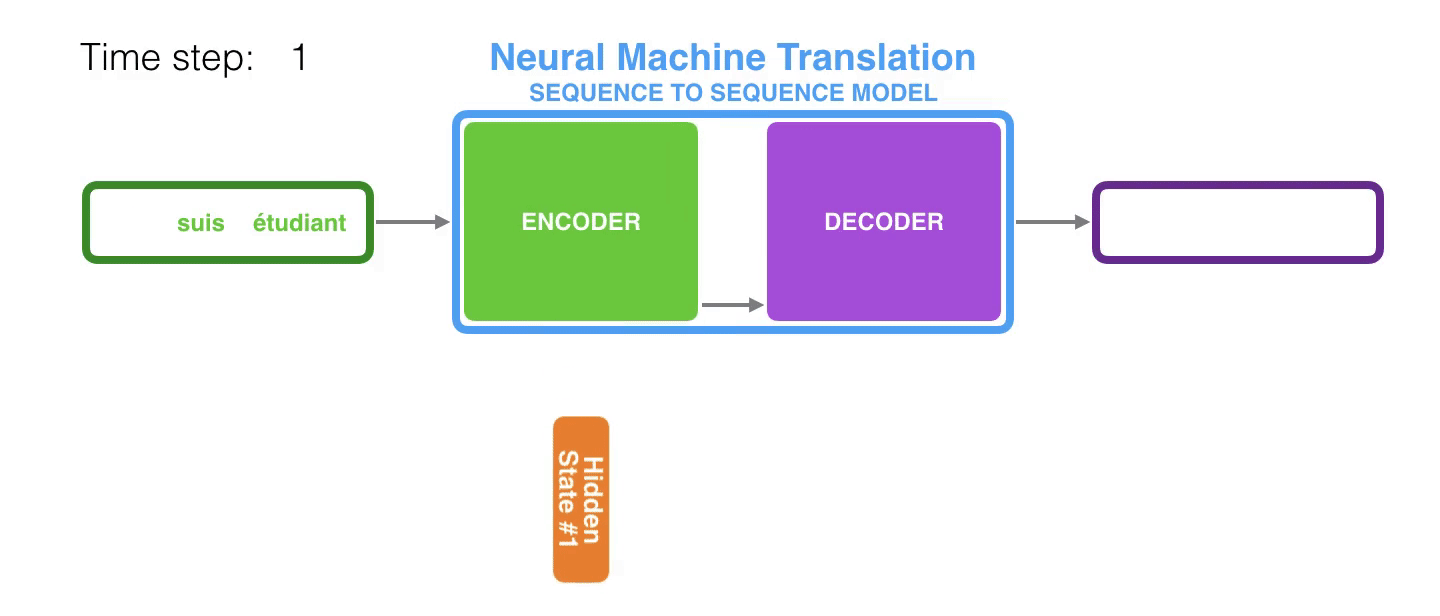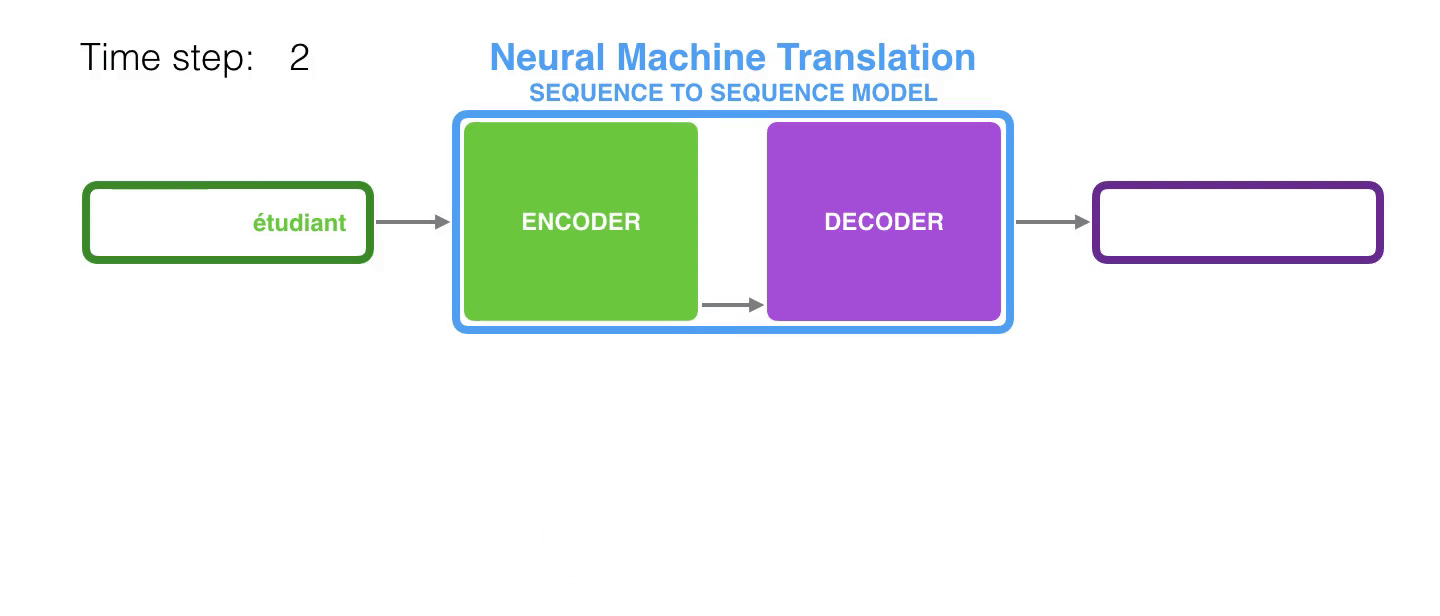
神经机器翻译,顾名思义,就是借助神经网络进行翻译模型的学习。翻译模型的输入是一个自然语言的句子,输入网络前这条句子被我们使用分词+word Embedding表达成一个带有时序信息的向量序列,然后经过网路的翻译之后,输出target方语言中word Embedding的一个概率分布,进而得到翻译好的句子。由此可见一般的神经机器翻译的套路。当我们借助大量数据来驱动这样一个模型训练时,输入的源语言和期望的目标语言这两个独立的向量序列构成了一个pair,然后使用损失函数就能够驱动模型进行学习的优化,指导模型收敛,能够将源语言下的句子翻译成比较好的目标语言。
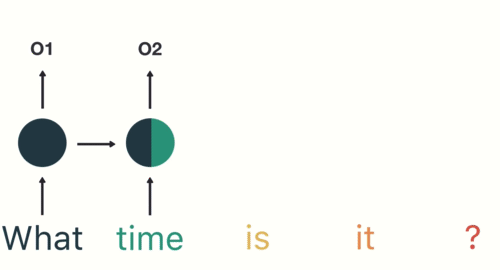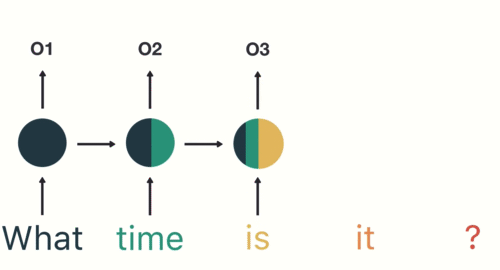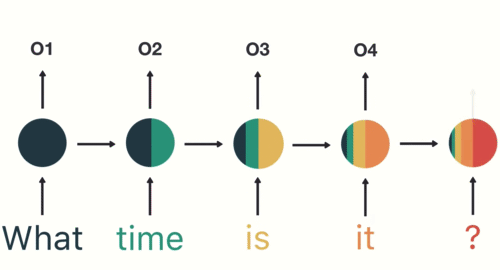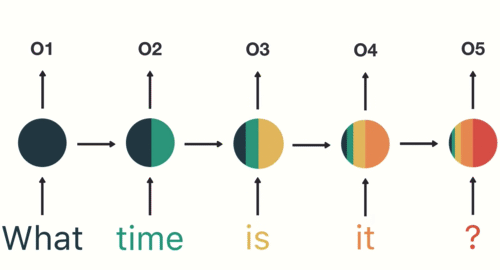
2. Seq2Seq模型的发展
在诸多可以用来学习数据特性的深度学习模型中,非常适合处理拥有时序特性的数据的模型有RNN,LSTM,GRU…,他们在序列数据建模中大放异彩。就神经翻译框架来看,外形是差不多的,只是用来编码和解码的基础构件不同。
2.1 基础的RNN
R(Recurent)NN其实有好几种villain版本。
- One-to-one
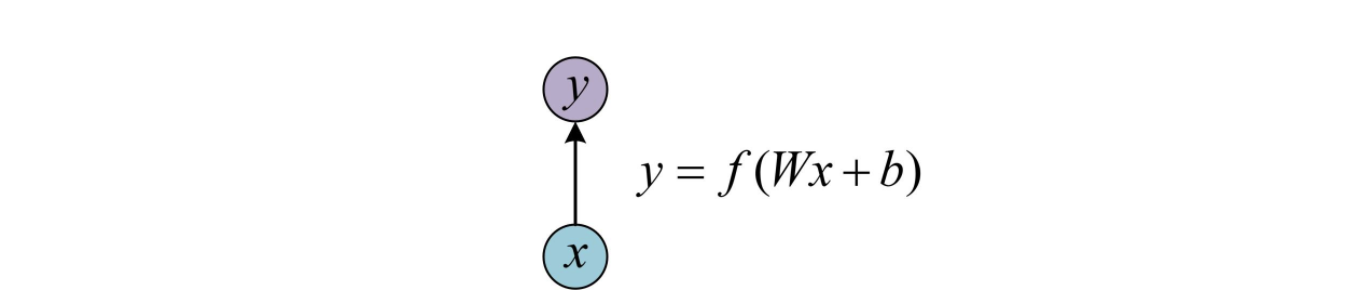
也就是最基本的单层网络,输入是x,经过Wx+b和激活函数f得到输出y。
- one-to-n
输入不是一个序列,但是输出是序列的情况。输入的注入方式可以只在序列开始时注入,也可以是每个时间步都将输入注入模型。
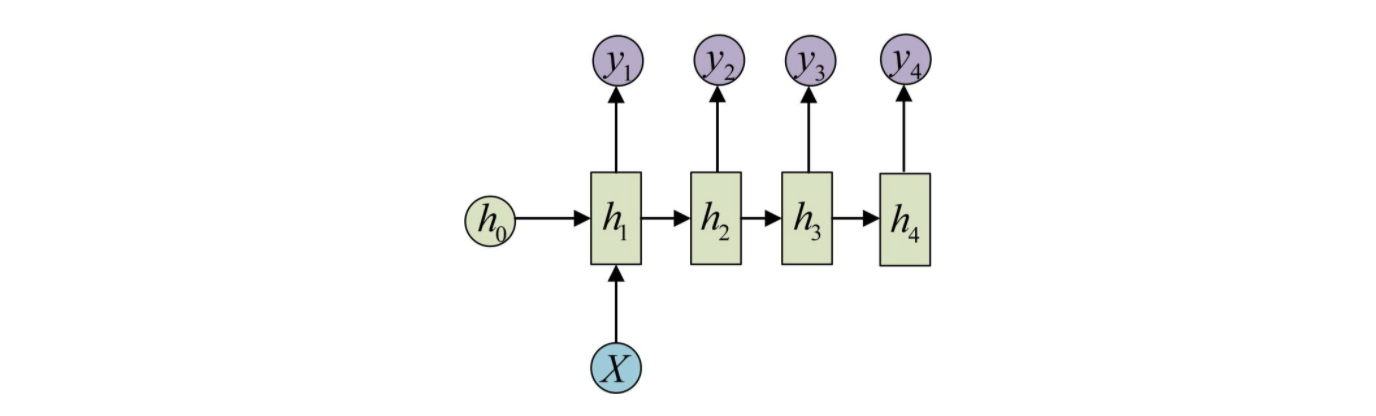
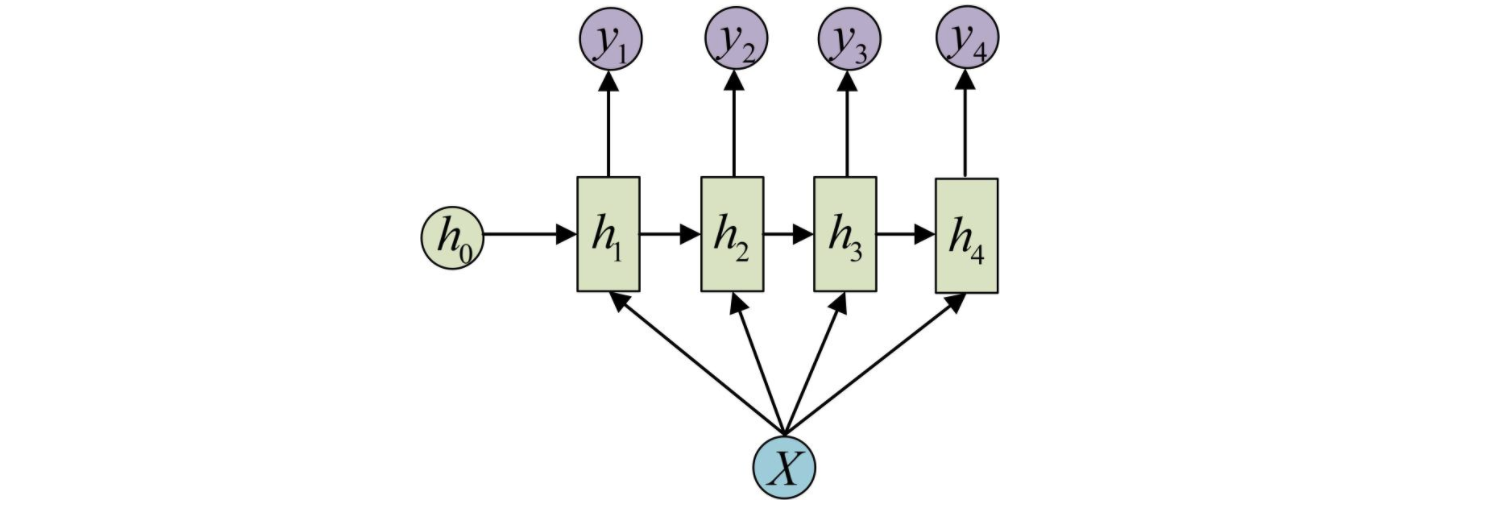
这种one-to-n的结构可以处理的问题有:
- :honeybee:image caption「从图像生成文字」,此时输入的X就是图像中抽取的特征,而输出的y序列就是一段句子。
- :first_quarter_moon:从类别生成语音或者音乐。
- n-to-n
最为经典的RNN结构,输入和输出都是等长的序列数据。假设输入X=(x1, x2, x3, x4),每个x是一个单词的词向量。

为了对序列数据进行建模,RNN引入了隐状态h(hidden state)的概念,h可以对序列形的数据提取特征,接着再转换为输出。先从h1的计算开始看:
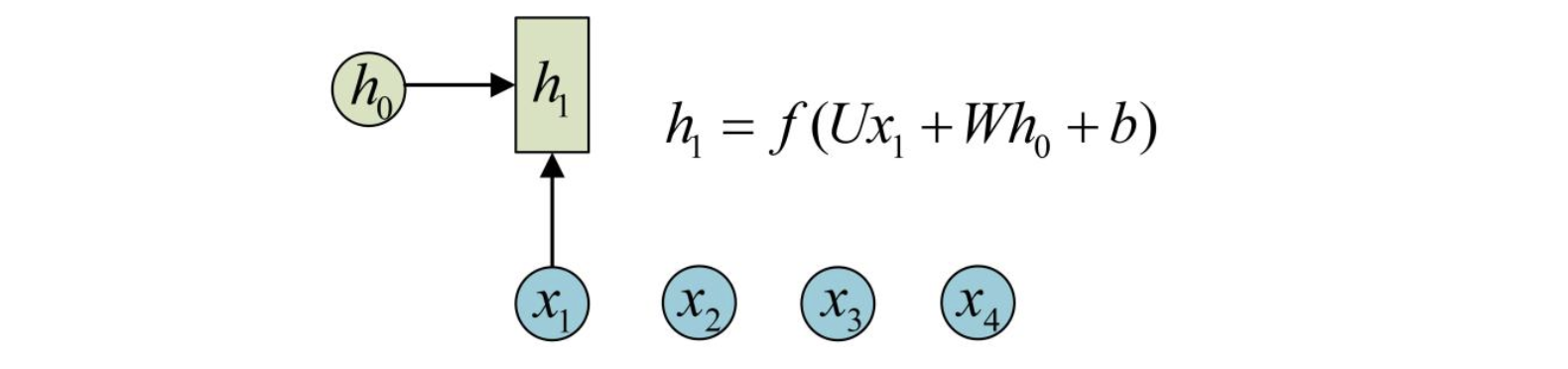
h2的计算和h1类似。Note:在计算时,每一个时间步使用的参数U,W,b都是重复使用的,这也是Recurent的由来,也就是说没个时间步中的参数都是共享的,这是RNN的重要特性。按照相同方式一次计算剩下来的隐状态(使用相同的U,W,b):
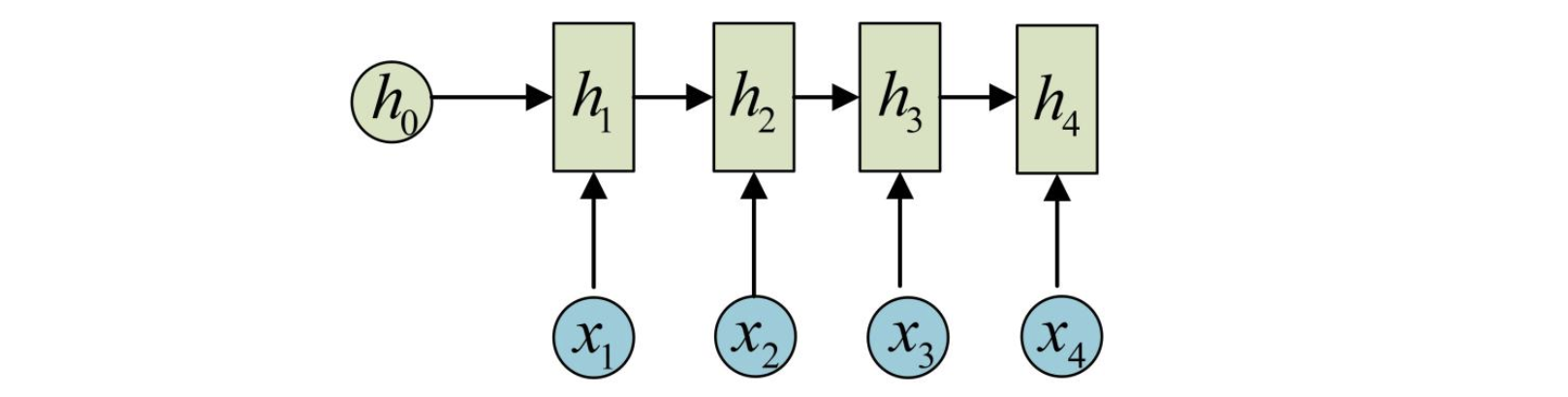
为了方便描述。在这里只画出序列长度为4的情况,实际上,You can play it all day。得到输出值的方法就是直接通过h进行计算:
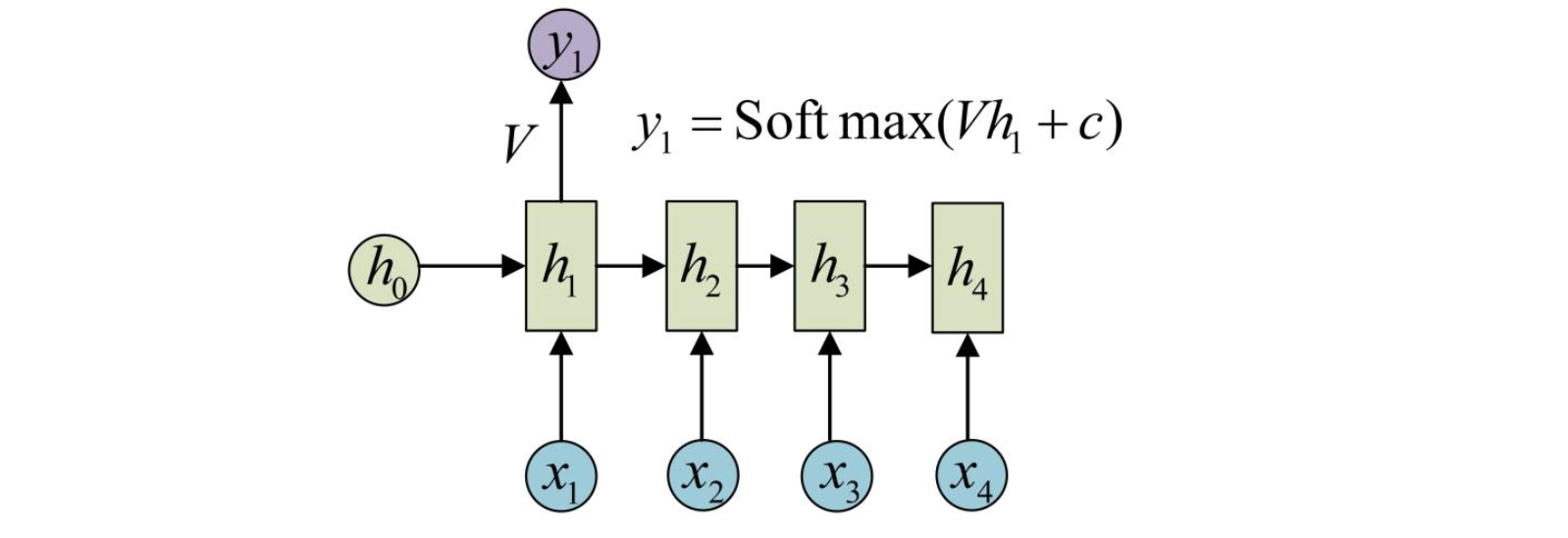
一个箭头就表示对对应的向量做一次类似于f(Wx+b)的变换,这里的这个箭头就表示对h1进行一次变换,得到输出y1。剩下的输出类似的进行(使用相同和y1相同的参数V和c)。
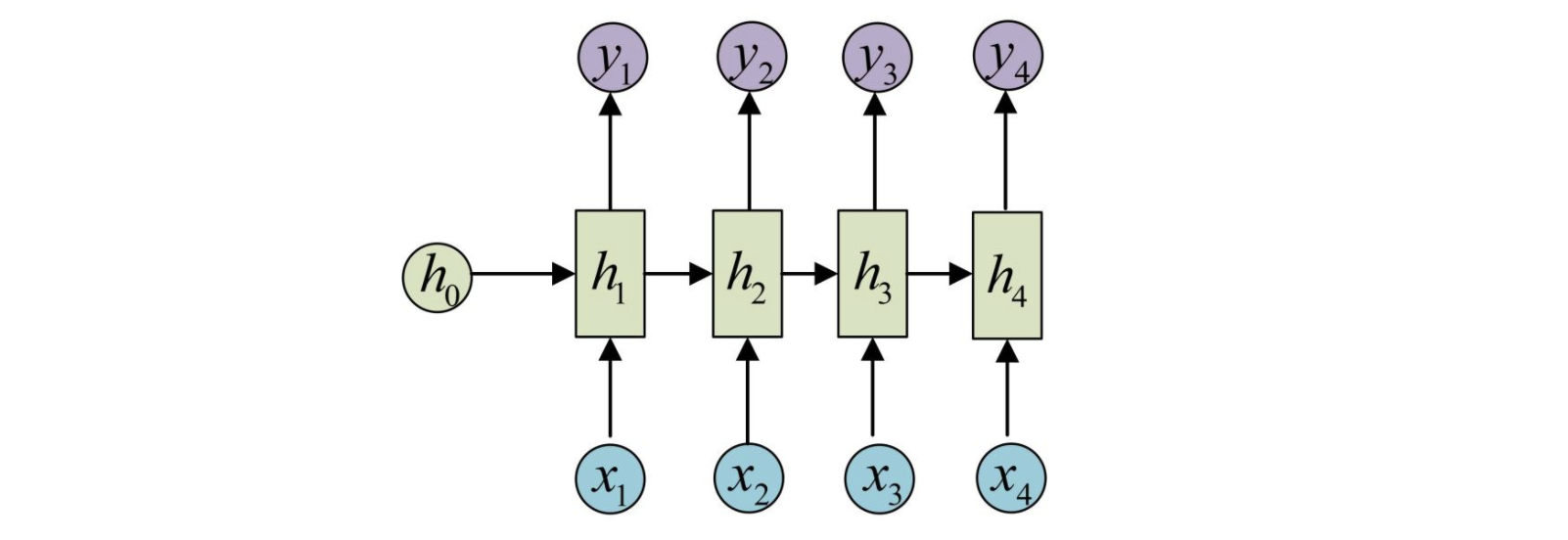
这就是最经典的RNN结构,它的输入是x1, x2, …..xn,输出为y1, y2, …yn,也就是说,输入和输出序列必须要是等长的。由于这个限制的存在,经典RNN的适用范围比较小,但也有一些问题适合用经典的RNN结构建模,如:
- :eagle:计算视频中每一帧的分类标签,这种情况下输入输出序列的时间长度相同。
- :rabbit2:输入为字符,输出为下一个字符的概率。这就是著名的CharRNN(The Unreasonable Effectiveness of Recurrent Neural Network),可以用来生成文章,诗歌,甚至是代码。
- n-to-one
要处理的问题输入是一个序列,输出是一个单独的值而不是序列,应该怎样建模呢?实际上,我们只在最后一个h上进行输出变换就可以了:
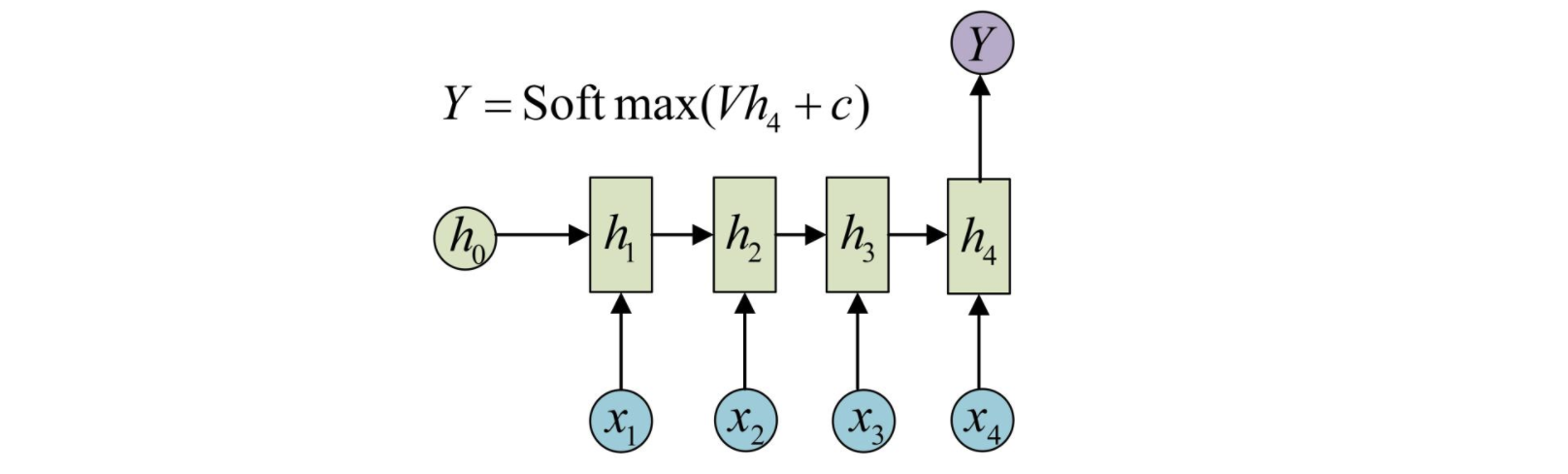
这种结构通常用来处理序列分类问题。如输入一段文字判别它所属的类别,输入一个句子判断其情感倾向,输入一段视频并判断它的类别等等。
- n-to-m
最后一种n-to-m的范式,就是久负盛名的Encoder-Decoder,它的输入和输出的序列长度不相等。Encoder-Decoder也叫做Seq2Seq。在机器翻译中,源语言和目标语言的句子长度往往不相同,为此,Encoder-Decoder结构先将输入数据编码成一个上下文语义向量c:
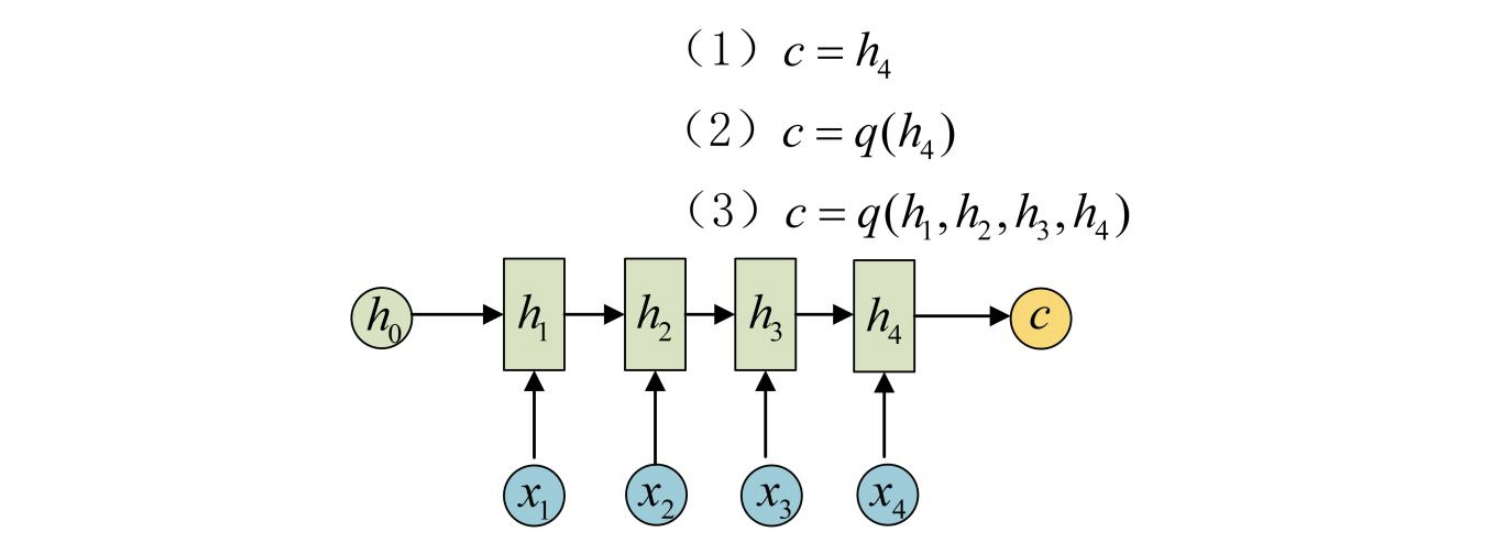
语义向量c可以有多种表达方式,最朴素的方法就是把Encoder的最后一个隐状态赋值给c,还可以对最后一个隐状态做些后续的变换得到c,也可以对所有的隐状态做变换。拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。Decoder的RNN可以与Encoder的一样,也可以不一样。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
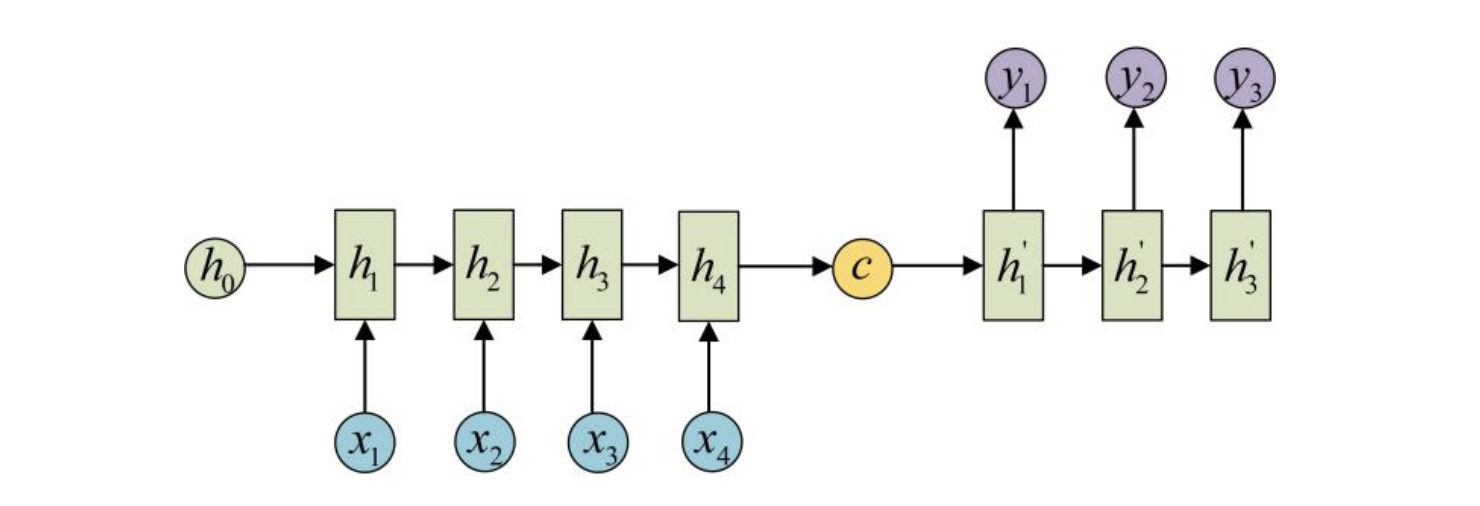
还有一种做法是将c当作每一步的输入:
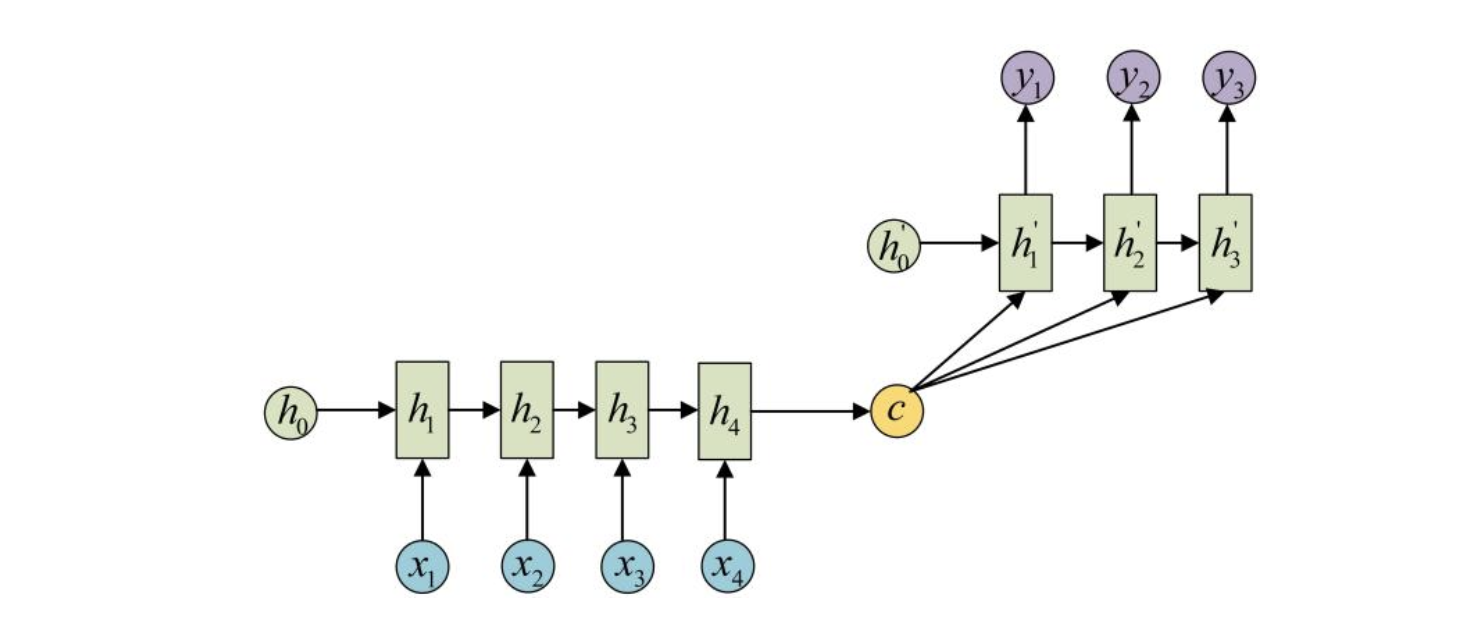
2.2 Encoder-Decoder的应用
由于这种Encoder-Decoder的结构不限制输入和输出的序列长度,因此应用范围非常广泛,比如:
- :walking:机器翻译:Encoder-Decoder的最经典应用,事实上,Seq2Seq结构就是机器翻译领域最先提出的。
- :earth_asia:文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列。
- :taco:阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案。
- :yum:语音识别:输入是语音信号序列,输出是文字序列。
2.3 Encoder-Decoder框架
Encoder-Decoder不是一个具体的模型,而是一种框架。
- Encoder:将输入的序列向量转换为固定长度的Embedding
- Decoder:将固定长度的Embedding转换为Output序列
- Encoder与Decoder可以彼此独立使用,实际上经常一起使用。
因为Seq2Seq最早出现在机器翻译领域,最早被广泛使用的基模型是RNN,其实基础模型可以是RNN,CNN,BiRNN,LSTM,GRU…
2.4 Encoder-Decoder缺点
- 最大的局限性:Encoder和Decoder之间的唯一联系是固定长度的语义Embeddingc。
- 编码器要将整个序列的信息压缩进一个固定长度的语义向量c。
- 语义向量c无法完全表达整个序列的信息。
- 先输入的内容携带的信息会被后来的信息稀释掉,或者覆盖掉,因为输入的序列长度太长时,编码器无法将所有输入的信息保留。
- 输入序列越长,这样的现象越严重,这样使得在Decoder解码时一开始就没有办法获得足够的输入序列,解码效果就会大打折扣。
因此为了弥补基础的Encoder- Decoder的缺陷,提出了Attention机制,来在很长的输入序列中建立Attention,建立近、中远程的token依赖关系,捕捉重点信息。
2.4 加入attention后
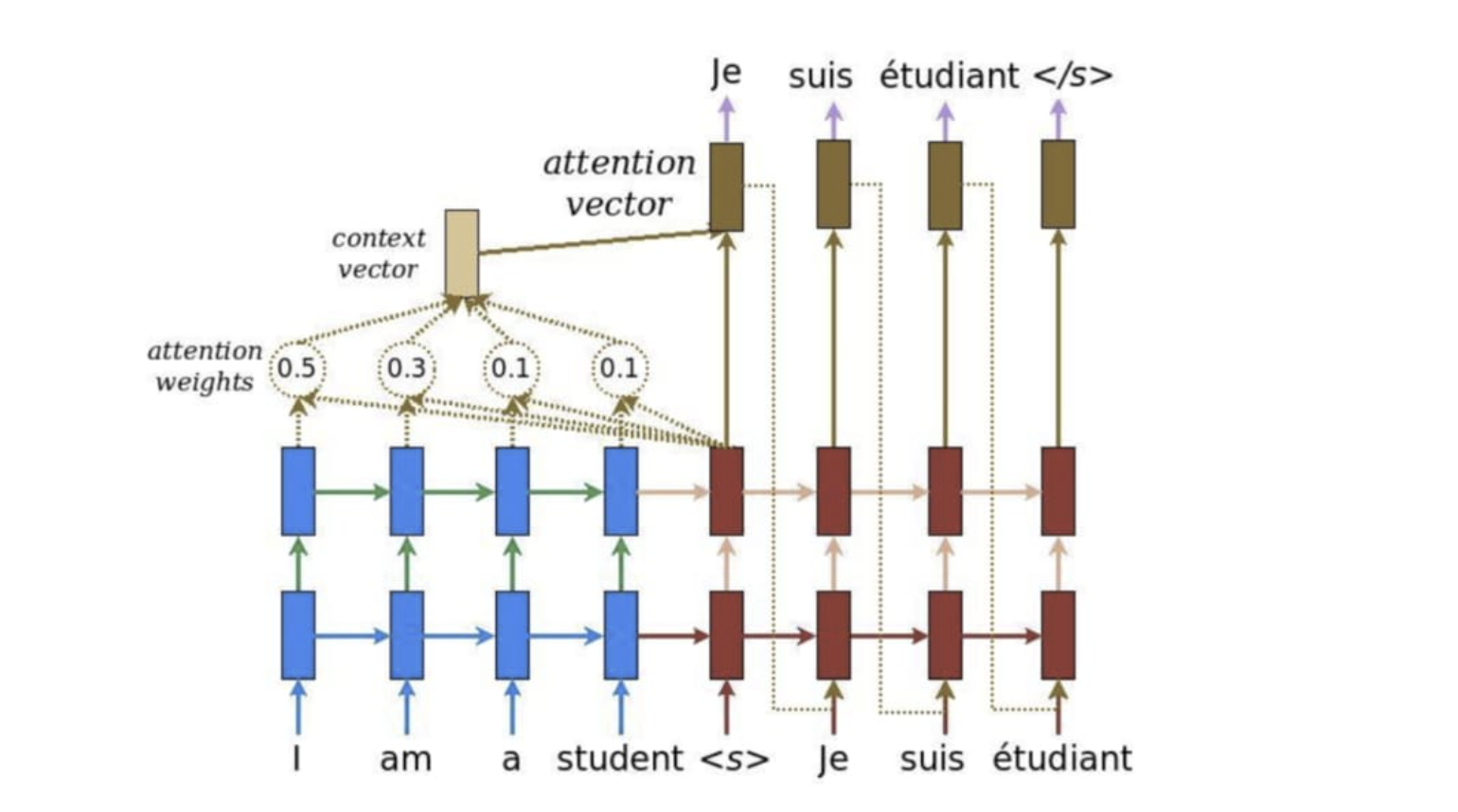
注意力机制是对基础Encoder-Decoder的改良。Attention机制通过在每个时间输入不同的c来解决问题,下图是带有Attention机制的Decoder:
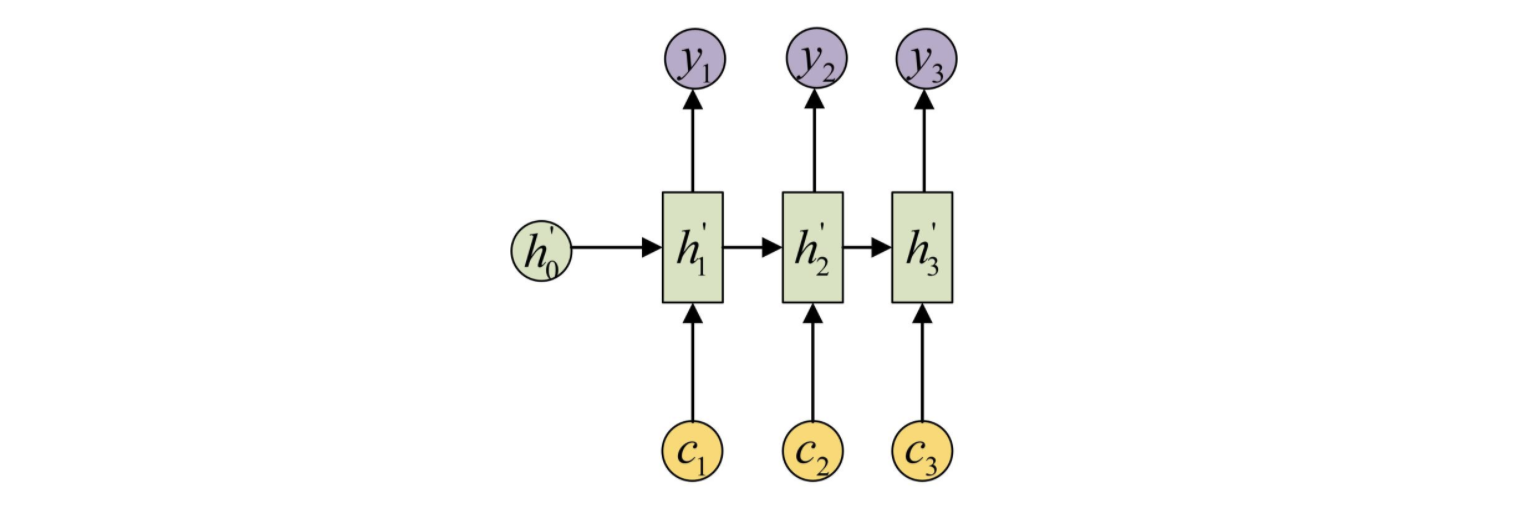
上图中的c不再简单的是Encoder最后输出的一个隐状态了,而是通过一个加权矩阵,将Encoder中所有时间步的隐状态$h_i$进行了加权整合,这个加权矩阵由Encoder中的n个隐状态$h_i$和Decoder中的m个隐状态$h_j^‘$计算相似度得出,是一个$n\times m$的矩阵。具体来说,我们用该矩阵中的元素aij衡量Encoder中第j阶段的hj和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息 ci就来自于所有 hj 对 aij 的加权和。
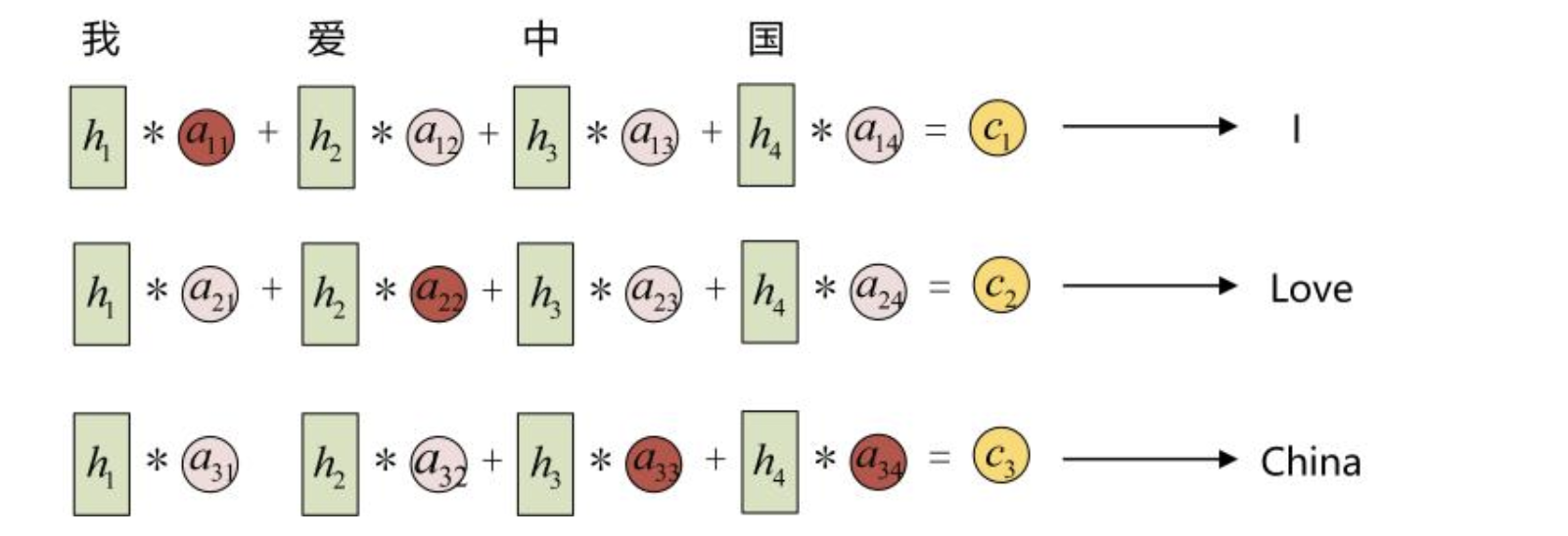
举个栗子,在上图中翻英的过程中,输入的中文序列的长度假设为4,输出的英文序列的长度假设为3,那么在Encoder和Decoder中分别会得到4个和3个隐状态,我们将其进行相似度的度量后,拿到了attention矩阵,然后将Encoder部分的隐状态通过这个attention矩阵进行加权,得到真正的往Decoder中送入的输入**$c_1$,$ c_2$, $c_3$**。整个过程就是这样的啦,可以看到加了Attention矩阵后,就算是再长的序列,我们也能将其中的信息通过attention矩阵很好的考虑进来。
2.5 attention的优点
- 在机器翻译时,可以让生词不只是关注全局的语义向量c,由于增加了注意力机制,可以让接下来的输出重点关注输入序列中的一部分,根据注意力区域来获得此时的输出。
- 不再要求Encoder将所有信息都编码到一个固定的global的向量中啦。
- 将输入编码成向量序列,Decoder时,每一步选择性的从序列中挑选一个子集进行处理。
- 在输出序列的每一个时间步上,借助attention从Encoder的诸多隐状态中整理出最有助于当前输出节点的语义向量$c_i$。也就是说,学习到的注意力是会随着上下文进行变化的。
2.6 attention的缺点
- 需要为每个输入输出组合分别计算attention。50个单词的输出输出序列需要计算2500个attention。
- attention在决定专注于某个方面之前需要遍历一遍记忆再决定下一个输出是以什么。
3. Encoder+Decoder+Attention和Transformer的关系
3.1 基础款RNN做Encoder- Decoder的缺陷
看起来Encoder- Decoder+Attention已经无敌了,可Transformer黄雀在后,进行了改进就表明基础编码器RNN是有改进空间的。
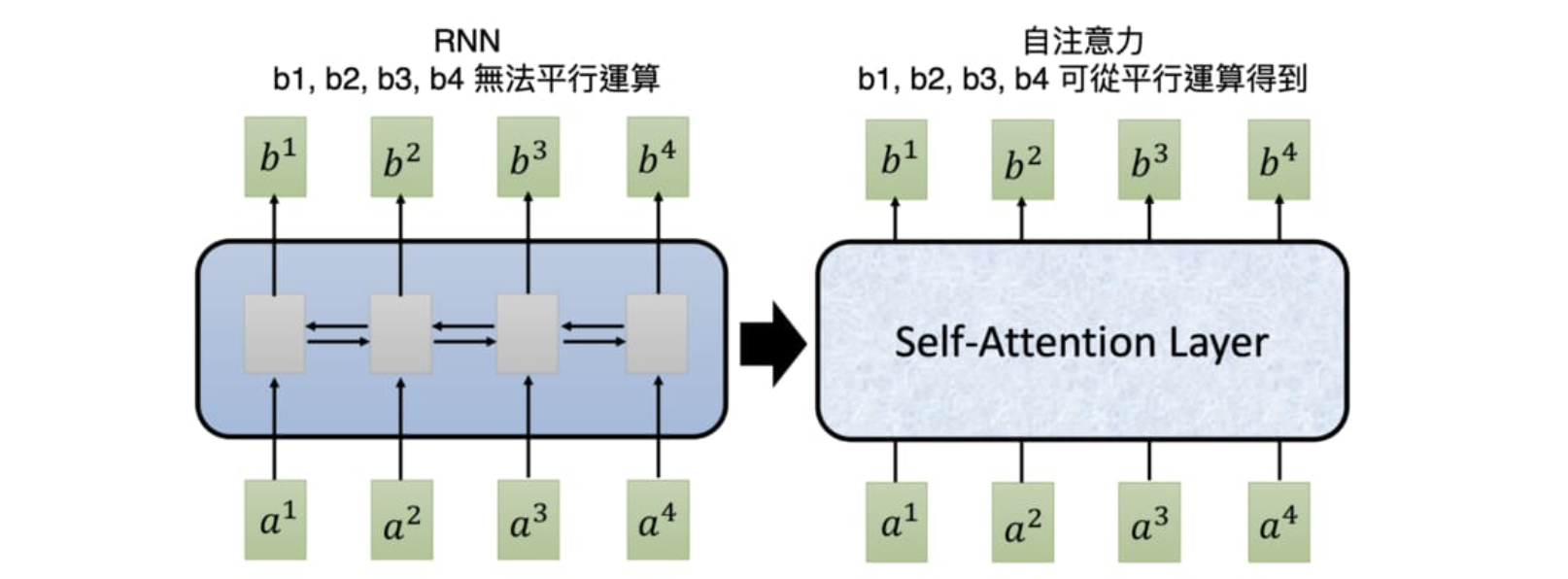
细细想一想RNN处理数据的模式,输入一个序列向量,要反复重用同一个参数组进行前传,就意味着,RNN处理序列数据时,现阶段只能是串行处理,即上一个时间点的输入被编码好之后,才能去处理当前时间点以及后续时间点的输入,这样的处理方式,让RNN在面对序列数据时丧失了高效的处理速度。或许,只有在编码时不去依靠先前时间步的输入能够让串行数据得到并行处理,而Transformer就是这样做的。Transformer在编码阶段将序列向量分离编码,然后在编码结束后,统一计算self- attention进行注意力的计算,然后再统一将计算得到的注意力作用到先前的分离编码上。这样的手段让串行数据向量能够在编码的同时,还能兼顾到上下文这个概念。相比起RNN反复recurrent的处理数据的手段,参数量是变大了,但确实能够并行处理了序列数据了。
3.2 Transformer做Encoder- Decoder的优势
说到这,Transformer的优势就不言而喻了。
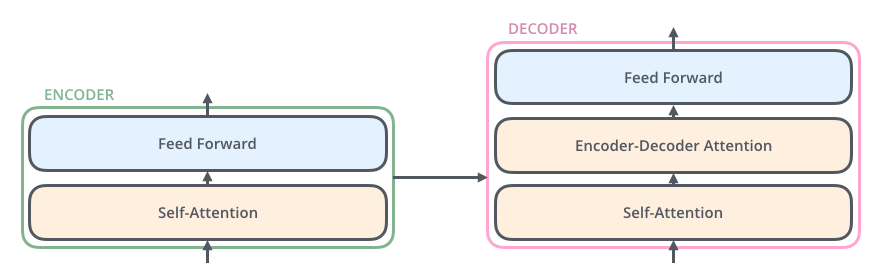
| RNN+Attention+ Seq2Seq | Transformer |
|---|---|
| Encoder中的隐状态承接上文信息,通过串行处理为上下文建模 | Encoder中通过self-attention为输入序列中建立attention,以此为上下文建模 |
| DEcoder中的隐状态承接上文信息,通过串行处理为上下文建模 | Decoder中通过self-attention为输出序列中建立attention,以此为上下文建模 |
| Encoder- Decoder通过计算attention来为输入序列的编码和当前输出建立注意力 | Encoder- Decoder通过encoder-decoder-attention为输入序列编码和当前输出建立编解码注意力 |
以Transformer为Encoder和Decoder的NMT系统,基本上可以分为6个步骤:
- Encoder为输入序列里的每个token产生原始的embedding,在上图中用空圈表示。
- 利用self-attention将输入序列中所有token的信息进行汇总,先计算得到attention,然后以此为权重,重新矫正加权过的每个token的embedding,上图中用实圈表示。
- Encoder重复N次self- attention,让每个token持续学习到完整的上下文语义。
- Decoder在生成输出文字时也运用了self-attention,关注自己之前时刻点已经生成的元素,将其上文信息纳入生成后续元素的过程中。
- 在Encoder和Decoder各自捕捉到上下文信息后Decoder接着利用attention关注Encoder的所有输出,并计算Encoder编码与Decoder之间的attention,并把这种连接Encoder和Decoder的注意力用来帮助生成当前时刻点的输出。「其实这个注意力才是上文RNN- based的Seq2Seq模型中加入的attention。」
- Decoder重复步骤4,5,来让当前元素包含到更完整的整体语义。
4. Transformer的内部运行机制
4.1 Transformer的Input和position Encoder
Input的表示方法
当我们进行机器翻译时,我们的输入输出是自然语言,所以第一步是要将语言表述成数学形式。
- 1-of-N embedding。这种方式是在一个封闭的词库里面,将出现的每个单词进行one-hot表述。
- word class。将相同类的单词放在一个class。(表示方式依然比较粗糙)
- word Embedding。把不同的词用一个vector表示,vector的每一维隐式的表示物体的某种性质。word embedding希望相同性质的词的embedding能够聚的近一些,不同性质的词的embedding能够离得远一些,换言之,word embedding其实是一种soft的word class。
位置信息编码
为什么要加入位置编码?我们的输入是一段带有时序信息的序列向量,但如果就这样把它放进Transformer的Encoder中进行特征的重表示,attention计算等等操作,它是会对序列信息不敏感的,换句话说,无论句子的结构怎么打乱,Transformer都会得到类似的结果。为了解决这个问题,就需要将位置信息显式的注入进输入。
位置编码也有绝对位置编码和相对位置编码等几种形式,在这里仅介绍绝对位置编码,通常这个位置编码的长度是和输入的序列向量同维的,这样方便位置编码和词向量逐位相加。
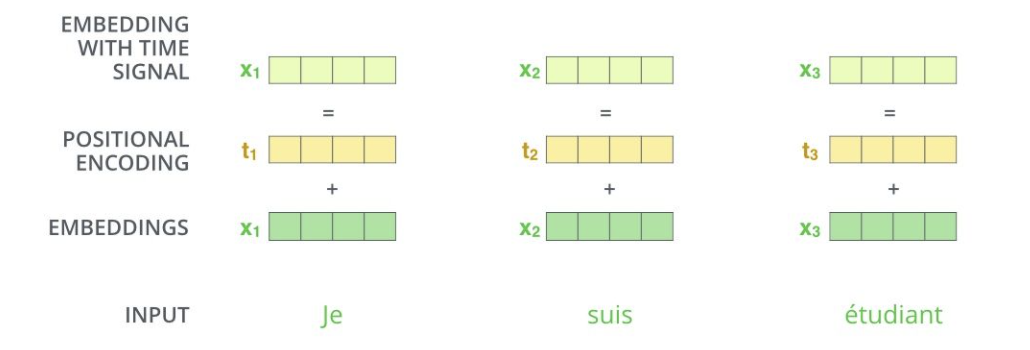
具体公式如下:
$$
PE(pos, 2i)&=sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}})\
PE(pos, 2i+1)&= cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}})
$$
在公式中,pos表示单词的位置,i表示单词的维度,关于位置编码的实现可以参看Google的实现get_timing_masignal_1d()函数找到对应代码。作者使用正余弦编码位置,是根据公式$sin(\alpha + \beta)=sin\alpha cos\beta + cos\alpha sin\beta$以及$cos(\alpha+\beta)=cos\alpha cos\beta -sin\alpha sin\beta$,这表明位置 k+p的位置向量可以表示为位置k的特征向量的线性变化,这为模型捕捉单词之间的相对位置关系提供了非常大的便利。
4.2 Transformer的Encoder
输入再编码
我们的输入数据X的维度是[batch_size, sequence_length],经过上面的词嵌入(word2Vec)后,我们得到的输入的size是[batch_size, sequence_length, embedding_dimension],embedding_dimension取决于Word2Vec算法,Transformer中采用的是512长度的字向量。比如我们得到了一些输入,他的shape是[3, 10, 512],Transformer的Encoder分别使用三个shape为[embedding_dimension, embedding_dimension]参数可学习权重矩阵Weight来分别乘以输入,将其再次通过LinearLayer对输入进行编码,这样我们就得到了所谓的Q(query),K(key),V(value)向量。
self-attention
通过第一步,我们得到了序列中的每个token的Q、K、V向量。然后Q向量和K向量先两两做内积,计算相似度,然后被$\sqrt {d_k}$进行归一化($d_k$是Q向量的维度长度),这样就得到了一个weight matrix,里面存了score,然后将这个score进行softMax处理,得到[0, 1]的一个分布,这时候的矩阵就是Attention了。然后将attention乘以V向量,就得到了包含了上下文信息的输出value。
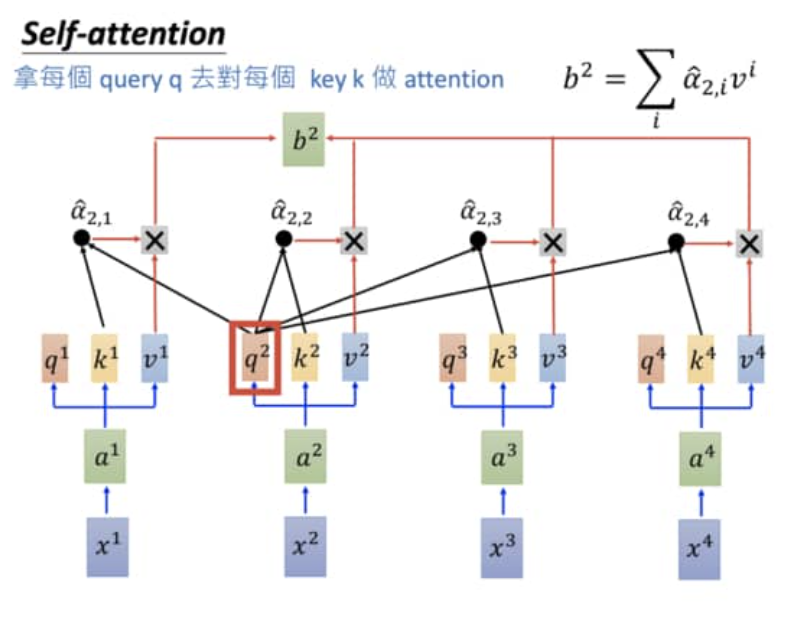 $$
Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt {d_k}})V
$$
$$
Attention(Q, K, V) = softmax(\frac{QK^T}{\sqrt {d_k}})V
$$
归一化(layer Normalization)+ skipConnection
由self-attention整合完上下文的信息后,得到输出后,要进行layer Normalization。在处理序列数据时,通常使用的是layer Normalization,而非Batch Normalization,因为序列数据通常长短不一,不同batch数据之间的gap通常存在于序列的长短中,而使用layer Normalization就能够越过长度不同这个问题。skipConnection是帮助网络收敛的惯用伎俩,即把输入短接到输出位置。
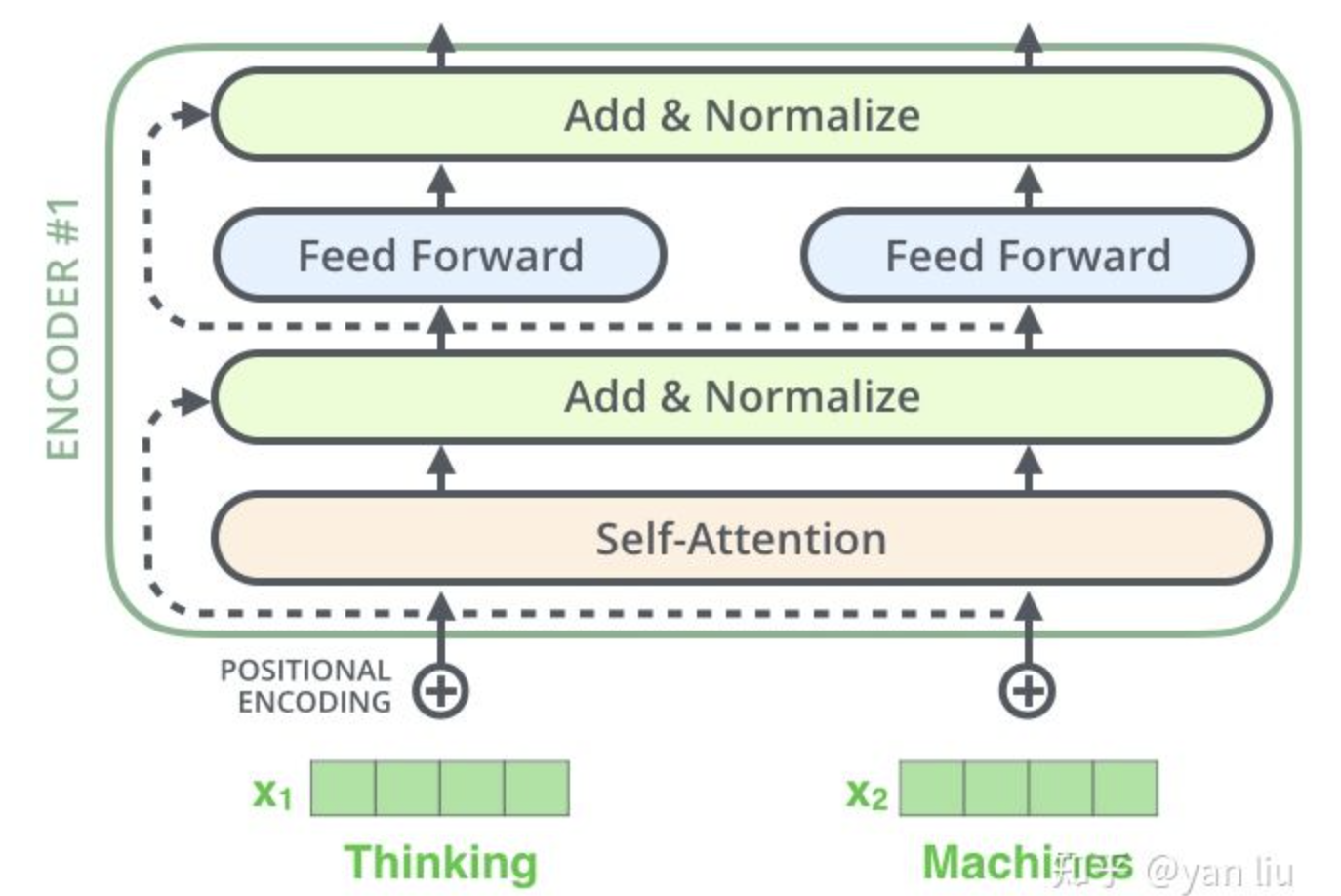
MLP(Feed Forward Network)
上图中Transformer- Encoder的最后一脚是feed Forward层,就是MLP,就是linear layer。他的作用是把向量的维度再次进行变化,尤其是我们下面将要说到的Multi-head Attention中会用到它来compress特征维数。
Multi Head Attention
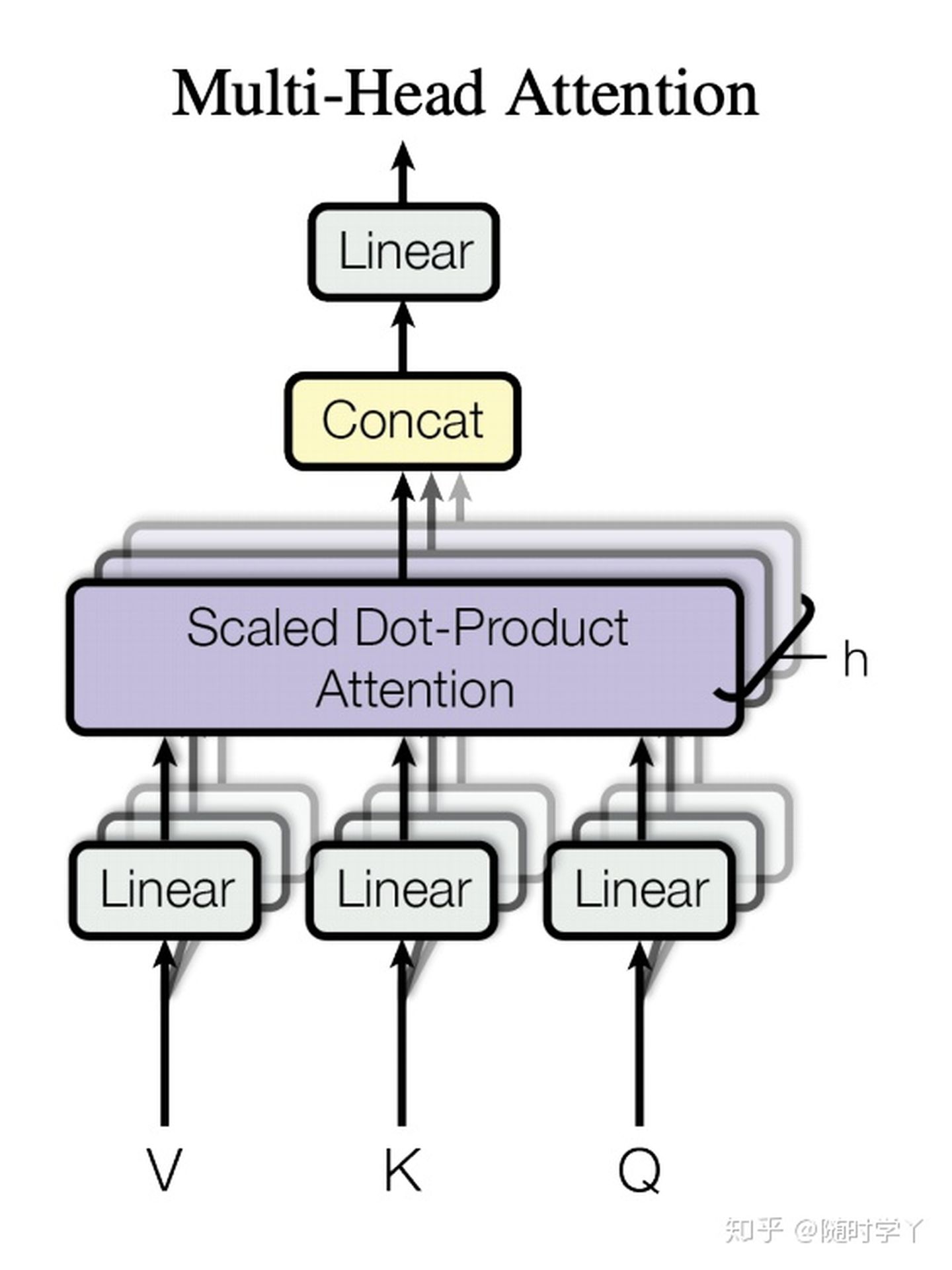
Multi- head- attention就是用h套参数组去做上面的事情(包括input再编码,self-attention计算及使用,Layer Normalization),然后将得到的h套结果concatenate到一起之后,使用Feed Forward Layer进行维度压缩,就是这样啦。
4.3 Transformer的Decoder
输入再编码
目标的输出序列也要进行再编码,假如输入的数据是[batch_size, seq_length]–>[3, 7]–>[batch_size, seq_length, embedding_dimension]–>[3, 7, 512],而期望的输出数据是[batch_size, seq_length]–>[3, 13]–>[batch_size, seq_length, embedding_dimension]–>[3, 13, 512],这时先要使用三个权重矩阵进行再编码。
输入mask处理attention
经过第一步处理后,得到序列向量的编码后,计算self-attention时,由于下文要输出的信息还未生成,只有上文的信息能够参与到attention中,所以要使用mask来mute掉attention矩阵中的下文关注,如下图中的Masked Multi-Head Attention所示。
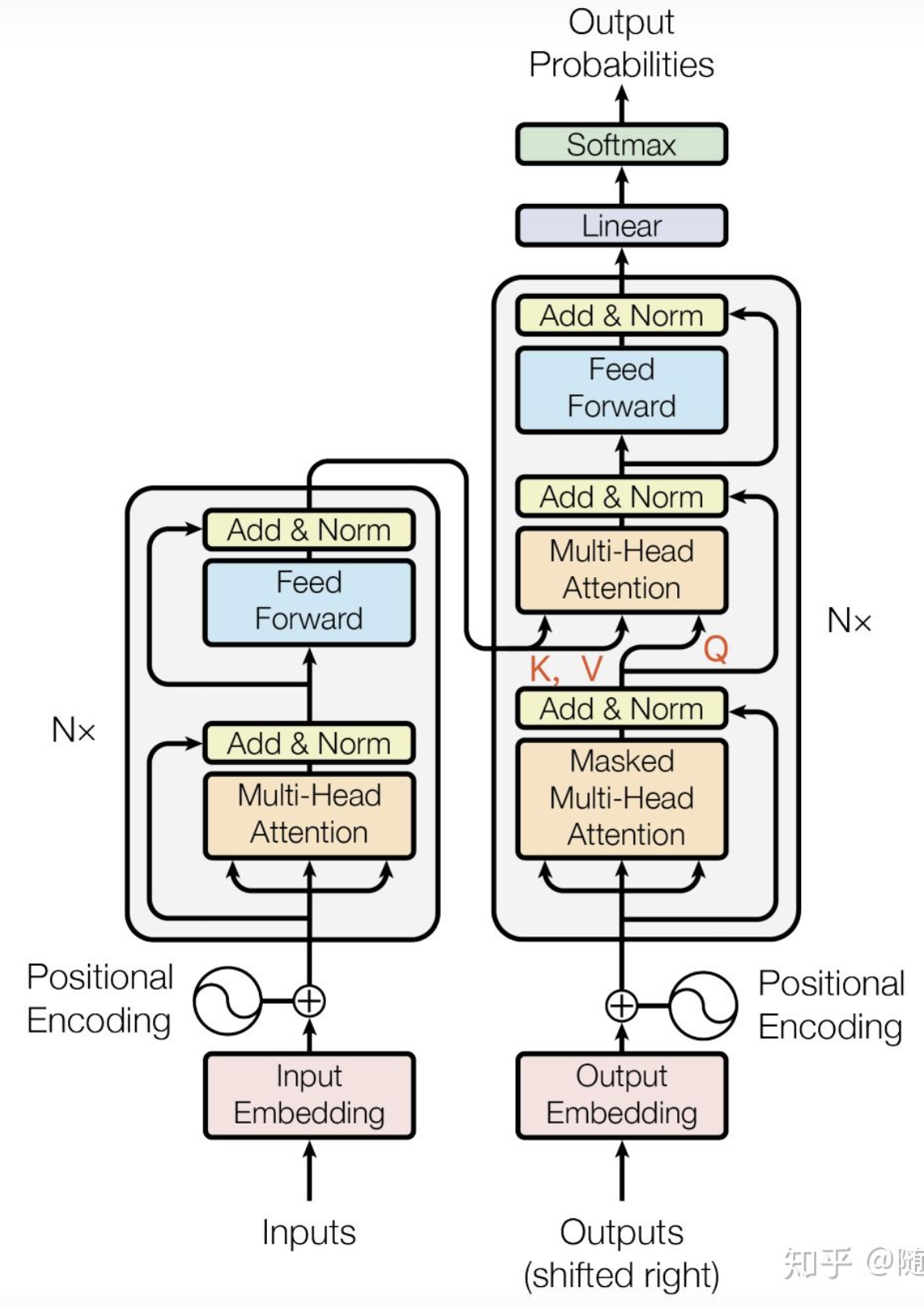
用Encoder-Decoder-attention矫正输入编码
和经典款的Seq2Seq模型中的attention关系最接近的就是Encoder-Decoder-attention了,他是Encoder与Decoder之间的关系和桥梁。用来度量输入序列向量编码和输出序列向量编码之间的alignment程度,即把输出序列向量作为key,去查询输入序列向量,得到attention后,通过attention聚合出能够最能帮助得到准确输出的V(value)。
4.4 Transformer的Training Process&&Inference Process
当进行测试时,Input Embedding可以完整的作为Encoder的输入进行特征表示,但是Decoder的输入侧所需要的Output Embedding需要从token**
作为开始输入,经过前向后,Decoder得到了下一个单词,然后将 和该单词连接共同作为Decoder的输入,再进行前向过程,经过一番for循环后,当Decoder得到的输出是 **时,翻译就完成了。 训练Transformer时,上图中的Input Embedding和Output Embedding都是完整的句子,但在Decoder中要注意为attention加mask来模拟当下想要的输出结果只能依靠上文信息来得到。其实训练过程应当是和测试过程保持一致,但为了减少训练过程的时间,我们做了并行化处理,例如我们的完整的OutputEmbedding是[[start], i , love, maching, learning] ,我们会乘一个下三角矩阵,得到的是:
[[start]
[start] i
[start] i love
[start] i love maching
[start] i love maching learning],训练阶段将这个矩阵直接作为GT,当作Output Embedding直接输入Decoder,分别可以得到5个输出$O_i, i\in[1,2,3,4,5]$,但理想的输出应该是[i, love, maching learning, [eos/],然后在$O_i$和理想输出间计算交叉熵损失,反传梯度驱动模型参数更新。
4.5 常见的Transformer大模型
- 「BERT」Bidirectional Encoder Representations from Transformers。其实就是大规模语料库在预训练任务上训练Transformer的Encoder。
- 「GPT」Generative Pre-Training。其实就是Transformer的Decoder。后来的GPT2可以做阅读理解,Summarization, Translation等,GPT3最近也开放了api接口的申请名单,但是没有中国昂。
 wechat
wechat alipay
alipay